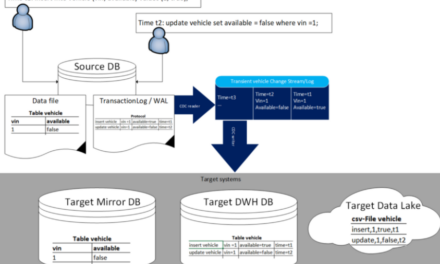
The need to model all data up front caused developers to tag relational databases with attributes like inflexible, dated, annoying, painful, etc. It is often not possible anymore to define a schema that remains stable for some revisions in case of continuous delivery and regular shipments. NoSQL or schemaless stores, in general, appear to be the solution for this dilemma. Additionally, the concept of a Data Lake just lets you dump data into a storage area without interpreting the schema during write time. Schema-on-read helps to apply a schema at the latest possible time when reading the data.
The flexibility of schema-on-read appears to be a bombastic advantage. As always, there are two sides of the coin. No or almost none data modeling up front and dumping data (into a Data Lake or NoSQL data store) without interpreting the schema leads to downsides, too:
- Flexibility for write but inflexibility for reading
The reader of the data has to do the work. In the worst case, two or more people do the same work independently from each other again and again. Additionally, the readers have to deal with schema evolution (see migration burden below). Users may apply the schema(s) improperly and deliver wrong results. A thorough test cycle will be missing if end users directly apply the schema and access the raw data. - High performance for insert operations but performance penalty for reads
Copying data as is into the NoSQL datastore is very fast without any overhead due to constraints. The reader is penalized though. The schema has to be applied during data retrieval causing an overhead, e.g. CSV- or JSON-files have to be parsed and interpreted during runtime. If reading data occurs much more often compared to writing, it should be considered if optimizing for reading performance is the better choice. - Data Quality
The stored data may be incomplete or incorrect. Such errors will only be noticed during data retrieval. If data loss or corruption needs to be avoided, schema-on-read might be the wrong choice. Log or sensor data regularly contain data issues due to bad measurements. Losing some data items of the time series may not be an issue. - Data Security
If data is just dumped into a Data Lake, sensitive data may be stored insecurely without anonymization or pseudonymizing. Additionally, if data needs to be deleted because of legal requirements, the cleanup efforts can turn out to be very time-consuming and costly.
Data migration burden
Schemas change – so the question is how to handle schema evolution in NoSQL stores? Let’s assume that there are JSON documents in two different versions available. Version 2 is the newer version and fully replaces version 1.
There are three general strategies:
- No migration / schema version variety
All versions exist together: version 1 and version 2 are stored together. The application logic has to handle all versions. The application logic may become very complex during the time as many old (or even all) versions have to be handled. The same is true for ad-hoc queries: the end-user needs to know all versions in order to write proper queries. Read performance will suffer due to code complexity. That’s the standard approach associated with schema-on-read. - Immediate migration / one schema
Existing data is migrated immediately. Version 1 is migrated to version 2 as soon as version 2 is available. That’s the standard approach with RDBMs but could also be followed with schema-on-read. Prerequisite is that new versions will get known. The migration cost can be rather high. At the end, all data will be migrated to the latest version. Read performance will be best if this option is followed. - Lazy migration
Migration of data to the latest version is done during data load/retrieval. Only data that is really needed is migrated. There is no unnecessary migration. The application logic may become very complex during the time as many old (or even all) versions have to be handled. The same is true for ad-hoc queries: the end-user needs to know all versions in order to write proper queries. Read performance will suffer due to code complexity.
Web-scale applications using Document Stores might opt to do lazy migrations for smaller schema changes and immediate migration for heavy schema changes.
No migration will be the preferred choice for many data sources filling a Data Lake, e.g. dumping log data from sensors or machines may be too much overhead to migrate to the latest schema again and again. It could make sense to follow a different migration strategy for different data sources.
Schemaless DBs are not a revolution – data migration burden will be real.
Maybe NoSQL stores will offer functionalities for schema evolution and data migration in future (and especially for schema extraction). Google implemented an interesting approach in their F1 database. Google F1 is a distributed database that handles schema changes asynchronously. Google AdWords uses F1 and has critical requirements regarding high availability and no data corruption. F1 is based on Google’s Key-Value store Spanner and maps relational tables to Key-Value pairs. F1 implemented a protocol to propagate schema changes. F1 is shared by many different teams at Google. Schema changes need to be published rapidly in order to support new features. Several schema changes are published together and the database determines the best order to avoid unnecessary reorganizations. Schema changes typically need 10-20min without reorganization and undergo various states like delete-only or write-only to prevent corruption.