DOAG Big Data Days 2018 took place in Dresden from 20-Sep-2018 to 21-JUN-2018 with talks around Data capital, Data catalog, Streaming, Kafka, Data Lake, visualization, and geodata. There was also a hands-on workshop about Big Data SQL and connectors.
This blog post summarizes some of my impressions.
Data capital, Data bankruptcy, and Data catalog
Jean-Pierre Dijcks talked in his keynote about data capital and data bankruptcy. The importance of data is indisputable. He made an analogy with financial bankruptcy for companies not succeeding in their data strategy or even worse having no data strategy. GDPR causes financial risks if data failures occur. Data-driven companies need to manage their data and increase its value. A prerequisite is to find the data which was addressed by my talk on metadata or better: data catalogs.
Just two weeks before the conference, Google announced Google dataset search. Google dataset search is for external data that use metadata as defined at schema.org. What about internal data?
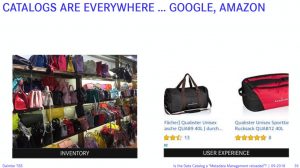
Technical and business metadata can be regarded as an inventory. But consumers care about user experience, e.g. how do other users rate product X? The same must be achieved with the inventory in data catalogs. Which data in which tables are regularly used and rated higher by e.g. data scientists? Liking of metadata and collaboration on metadata objects must be possible in a Data Catalog to enable rating of internal data – an Amazon-like style for data. Collaboration and sharing knowledge about data is essential. Automation is necessary to generate recommended descriptions or linkage of objects as nobody will be able to document everything. Usage of Machine Learning and analysis of data accesses is required to automate such labor-intensive work.
The following table lists some companies with their current activities around building their own internal data catalogs. Google, LinkedIn, Netflix, Uber – just to name a few companies that realized the importance of that topic. BTW, Linkedin’s data catalog is open source.
|
Company |
Link |
|
Netflix (Metacat) |
|
|
|
|
|
LinkedIn (WhereHows) |
|
|
Google (Goods) |
https://ai.google/research/pubs/pub45390 https://www.buckenhofer.com/2016/10/goods-how-to-post-hoc-organize-the-data-lake/ |
|
Uber |
|
|
eBay |
Cataloging of data incorporates not only RDBMS metadata with well-known structures like tables and columns. Relational tables clearly separate data and metadata. Cataloging is also or even especially necessary for NoSQL DBs or Hadoop files which have their own challenges with schema-on-read. Data and metadata are mixed within the same file. Does a date in a log file belong to metadata or data? Are the geocodes in a tweet metadata or data?
Oracle Autonomous Database
Ulrike Schwinn talked about the Oracle Autonomous Database which is available as an
- autonomous transaction processing database and
- autonomous data warehouse (ADW).
Ulrike focused on explaining the ADW including a demo session. ADW is an Oracle Database 18c on Exadata Cloud infrastructure. Therefore features as listed in the picture are available.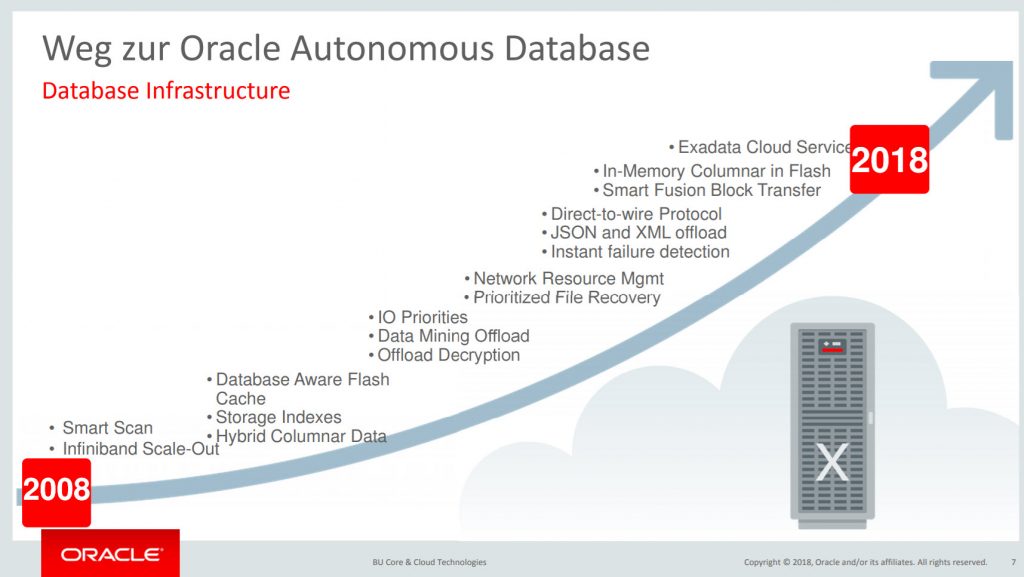
Oracle uses multitenant to provide a single PDB as an ADW database. The CPU count can be adjusted dynamically and also set to 0 to avoid costs for computation. Storage costs will accrue though.
The question about the future of the DBA came at the end of the session. Ulrike reminded the audience that similar concerns came up regularly in the past, e.g. with the Oracle advisories that help in many cases but do not replace DBAs. DBAs will still be required as not everything will be “self-driving”. Such tasks might be: Tuning poorly written SQL statements, figuring out how to optimally load data or helping to decide on the appropriate database architecture to use. DBAs will get rid of monotonous, repeating tasks and they need to take the next step to automation. DBA job profiles will change – as they already did in the past. The world is in constant change.
Kafka, KSQL, and streaming

Guido Schmutz had three sessions on Streaming. One of his sessions was about KSQL and Kafka. KSQL enables real-time data processing against Apache Kafka using SQL-like syntax and semantics. KSQL operates on data within the Kafka broker. Data can be accessed as STREAM or TABLE. The slide summarizes the idea behind STREAMs and TABLEs.
STREAMs and TABLEs can be used in SQL statements and joins can be made.
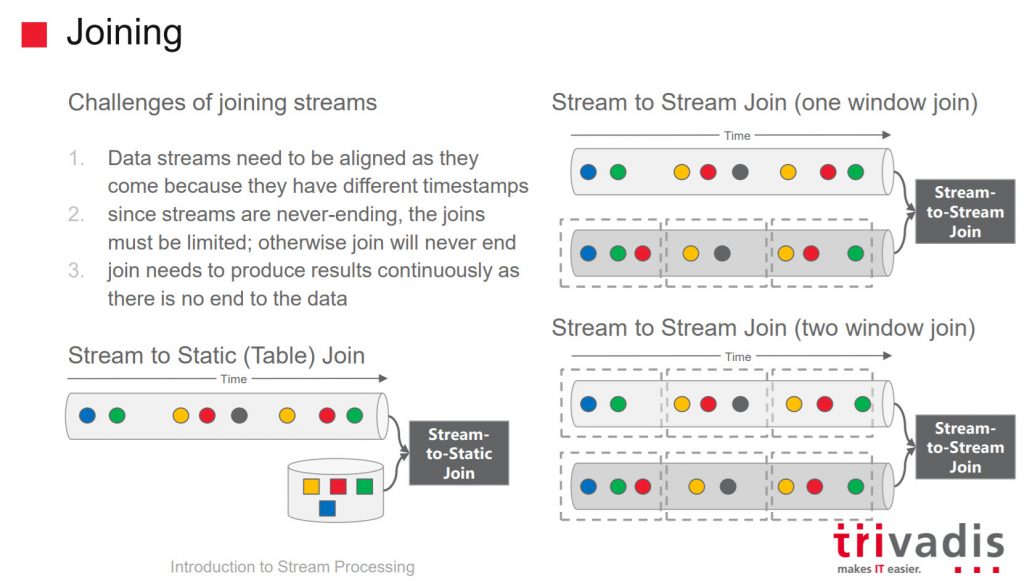
Guido showed several demos on STREAMs and TABLEs. As STREAMs are never-ending, joins must be limited to a time frame.
KSQL is a great way to work with streaming data for people familiar with SQL. Instead of writing a lot of program code, maintainable and understandable SQL statements are possible. KSQL definitely lowers the bar to enter Kafka and stream processing.
There were much more great sessions during the two days. Networking was possibly throughout the session or at an evening event in Pizzeria „L‘Osteria“. I’m looking forward to the 6th DOAG Big Data Days in 2019.
