Kevin Meade is the author and publisher of his own book “Oracle SQL Performance Tuning and Optimization” – It’s all about the cardinalities”. His book is rather unknown as there is not much marketing about it. Unfortunately. Because it is a great book for the SQL tuning practitioner with many ready-to-use scripts and explanations.

His central approach to SQL Tuning is the filtered rows percentage method. The idea is to remove as many rows as early as possible in query execution. There are two options in general:
- optimize for the least number of rows after a join
- optimize for the least percentage of rows after a join
There are four parts of a query optimization that need to be taken care of:
- driving table: the first table to start the execution access. That’s the table with the highest filtered rows percentage
- join order: the order to access all tables in a query with the goal to keep the intermediary results as small as possible
- access method: how to read the rows, e.g. index access
- join method: how to join two tables, e.h. nested loop join, hash join, or merge join.
Why is it necessary to know about the filtered row method as that kind of optimization is actually the database optimizers task?
The DB optimizer follows similar strategies to derive an optimal execution plan. As the optimizer will compute an optimal plan most of the time, there are cases with bad performance. In such cases, the optimizer often does not derive an optimal plan. And now the SQL tuner (DBA, developer, …) comes into play to analyze the performance issue. It is helpful to follow a systematic approach and to know how a query should be executed ideally. The SQL tuner can compare his solution with the optimizers solution and he can take directed measure to help (force) the database optimizer to derive a better plan.
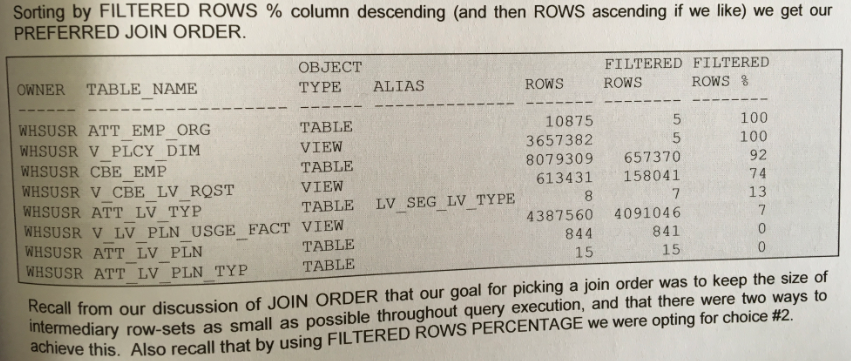
Kevin Meade supplies many scripts to help analyze a SQL performance issue. He explains the scripts and their output in his book. The diagram shows an example of the above mentioned “driving table”. The last column contains the information about the highest percentage of row filtering. The table with the highest percentage should be taken as the driving table.
He also covers different kinds of queries that require specific optimization techniques: precision style queries that return a few rows only and warehouse style queries that return many rows or as he summarizes:
- precision style query vs warehouse style query
- short query vs long query
- index lookup vs table scan
- first rows vs all rows
- …
- Indexing for access vs filtering vs coverage
- Each join method (nested loop join, hash join, merge join) has conditions in which the join performs better compared to the other join methods
- 2% rule of thumb: if a query returns more than 2% of rows, consider Full Table Scans as the better choice compared to index lookups. It’s a rule of thumb, so don’t take it as granted and always examine the current conditions
- Full Table Scans are very often good for warehouse style queries. Full Table Scans shouldn’t be considered as evil anymore. But always understand what kind of query style you have.
The book focuses on Oracle database but his method is also applicable to other RDBMS though not his scripts. Dan Tow wrote a book about “SQL Tuning” in 2003. Dan Tow’s book is database independent and contains many basics to derive an optimal execution plan. Dan Meade not just complements Dan Tow’s book but goes into much more database specific details as databases also added or improved many new optimizer features since then, e.g. Hash Joins. Both books are really worth while to work through.