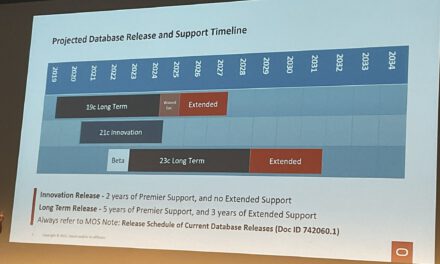
Michael Stonebraker and Andrew Pavlo wrote about DBMS innovations in their paper “What Goes Around Comes Around… And Around…” which revisits the evolution of data models and database systems over the last 20 years, examining trends and innovations in relational and non-relational database management systems (DBMSs). The paper explores two key areas: the continued dominance of SQL and the relational model (RM), and innovations in DBMS implementations driven by changes in hardware and application demands. The central thesis is that while various attempts have been made to replace SQL and RM, they have consistently absorbed innovations from competing models, thereby maintaining dominance.
Historical Perspective
In 2005, the authors reviewed several data modeling trends from the 1960s onward, including hierarchical, network, and object-oriented models. They concluded that the relational model, particularly in its object-relational form, had outlasted its competitors due to its extensibility and adaptability. Fast-forward to the present, relational DBMSs remain dominant, while other data models have either become niche or absorbed into relational systems.
The paper reiterates that while alternatives like NoSQL, MapReduce, and Key-Value stores initially presented compelling new architectures, they either converged with SQL or were absorbed by SQL-based systems. Furthermore, the major advancements in database systems have primarily occurred in RM implementations, influenced by hardware innovations.
The Continued Evolution of SQL and RM around DBMS innovations
The first section of the paper focuses on data models and query languages, showing that SQL and RM have survived multiple attempts at replacement by evolving to incorporate beneficial ideas from alternative paradigms. The key areas discussed are:
- MapReduce Systems: Initially a powerful alternative to RDBMS for certain workloads, MapReduce’s lack of a structured data model and complex query handling led to its decline. Systems like Hadoop were outperformed by RDBMS, and the remaining MapReduce-like systems now offer SQL interfaces.
- Key-Value Stores: These stores, such as Amazon DynamoDB and Memcached, were designed for scalability and performance in specific use cases but lack the flexibility of RDBMS. Many have adopted SQL-like interfaces as their feature sets have grown more complex, blurring the line between KV stores and RDBMS.
- Document Databases: While initially touted as a replacement for SQL, most document databases, such as MongoDB, have adopted SQL-like query languages and ACID transactions, pushing them closer to traditional relational systems.
- Column-Family Systems: Google’s BigTable and similar systems are essentially specialized document stores that offer lower-level APIs, often for specific use cases. These, too, have moved closer to supporting relational-like functionality over time.
- Text Search Engines: Systems like Elasticsearch and Solr are still specialized for text search but are increasingly integrating with RDBMSs, highlighting a trend toward multi-model data systems.
- Array Databases: Though useful for scientific computing, array databases like SciDB remain niche, and there is limited adoption outside specific verticals.
- Vector Databases: These new systems support embeddings from machine learning models, enabling high-dimensional similarity searches. The paper predicts these databases will follow the path of other NoSQL systems, gradually adding SQL support and converging with RDBMSs.
- Graph Databases: Specialized systems like Neo4j and Tigergraph are used for graph analytics, but many graph queries can be simulated in relational databases, which now offer graph query capabilities. SQL extensions such as SQL/PGQ further blur the lines between relational and graph DBMSs.
The authors emphasize that many of the once-differentiating features of non-relational systems have been adopted by SQL, making SQL systems increasingly versatile. SQL has evolved by adopting JSON support, vector indexes, and property graph queries, indicating that it is far from obsolete.
Advances in DBMS Architectures
The second part of the paper discusses how DBMS architectures have adapted to modern hardware and cloud environments. Major innovations include:
- Columnar Systems: Column-oriented DBMSs, such as Amazon Redshift and Google BigQuery, have taken over the data warehousing market. Their storage format is well-suited to analytical queries, offering superior performance compared to row-oriented systems.
- Cloud Databases: The shift to cloud computing has led to the development of cloud-native DBMS architectures, such as serverless databases that decouple compute and storage. These architectures enable elastic scalability and have become the de facto standard for modern applications.
- Data Lakes and Lakehouses: Data lakes, which store raw data in distributed object stores, have gained popularity for analytical workloads. Lakehouses combine the advantages of data lakes with the query capabilities of traditional data warehouses, offering a unified platform for both structured and unstructured data.
- NewSQL Systems: NewSQL systems aim to combine the scalability of NoSQL with the strong transactional guarantees of SQL. However, adoption has been slow, as existing RDBMSs have been “good enough” for many organizations.
- Hardware Accelerators: The paper discusses the limited success of specialized hardware accelerators for DBMSs, such as FPGAs and GPUs. While these offer performance improvements, they are costly and not widely adopted outside of specific industries.
- Blockchain Databases: Blockchain databases are viewed as a niche solution for specific use cases, such as cryptocurrencies. The authors argue that blockchains offer no meaningful advantage for most enterprise workloads, which can be more efficiently handled by traditional RDBMSs.
Predictions for the Future
The authors conclude by reiterating that the relational model, enhanced by SQL, will continue to dominate for the foreseeable future. They expect SQL and RM to remain the preferred choice for most applications, absorbing innovations from other data models as needed. Furthermore, while new DBMS architectures will continue to emerge, most will eventually converge with relational systems as SQL continues to evolve.
The paper also highlights the importance of the cloud in shaping the future of databases. Cloud-native architectures, serverless computing, and data lakes will dominate the landscape, providing organizations with the scalability and flexibility they need. Finally, the authors discuss the potential impact of artificial intelligence and machine learning on databases, noting that while these technologies offer exciting possibilities, they are unlikely to replace traditional DBMSs in the near term.
In conclusion, the evolution of databases over the last 20 years has largely followed a cyclical pattern. Despite repeated attempts to replace SQL and the relational model, these technologies have absorbed the best ideas from alternative paradigms and continue to dominate the market. The authors predict that this trend will continue, with SQL and RM remaining central to the future of database systems. Currently, vector technology is the hot topic that is also absorbed by SQL and relational DBMSs.