The annual DOAG 2017 conference took place from 21-NOV-2017 to 24-NOV 2017 in Nuremberg. As usual, the conference was great with 450 sessions and a comprehensive community schedule. Core database topics are still covered by the majority of sessions but also with a focus on trends like cloud, digitization, internet of things, or analytics. The conference also celebrated its 30th anniversary.

Robert Schröder hold an impressive keynote on error management. He is an active aircraft captain, training captain, and flight safety manager. Some of his main messages:
- Zero errors are an illusion – humans are always involved
- In case of an emergency, people will fall back to Know-How from training and not to extracurricular forces
- Hierarchical organizational cultures prevent error management with learning from mistakes and suppress critical but highly valuable questioning from subordinates during disasters

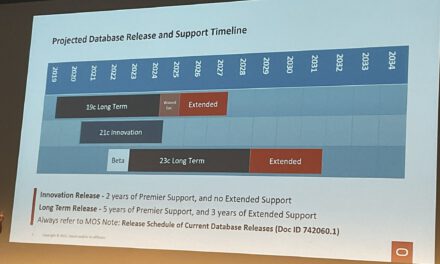
Some sessions covered a preview on the upcoming Oracle Release 18c. Data Warehousing and DBIM (Oracle Database In-Memory) will be a main part of the first autonomous database service. Hopefully all new features will be available on-premises, too.
DBIM is a dual format architecture built into Oracle’s core to make data accessible for queries in a row and in a columnar format. Oracle 18c is expected to ship with the following new key features (please note these are expected new functionalities … some feature may not come at all or in a later release; some features may only be limited to Cloud-only or Exadata-only … hopefully all features will be available on-premises, too):
In-Memory processing on external tables
External tables were already introduced in Oracle 9i and are available since a long time (just for comparison: Facebook started developing Hive in 09/2008 and the first version V0.3 was release in 10/2010). External tables can now be enabled for In-Memory processing by setting the keyword inmemory during create table or running an “alter table xxx inmemory” command. Features like SIMD and JSON expressions will be available. Especially JSON support is an important functionality as external data comes often in JSON format.
Automatic In-Memory
Data will be automatically classified as hot, intermediate and cold. Hotter In-Memory tables will be automatically populated into the In-Memory column store while colder data will be removed from it. The new parameter inmemory_automatic_level switches the feature on and off. The feature replaces manual, static placement of data into the In-Memory column store.
In-Memory dynamic scans
A single scan process will be able to scan several subsets of data in parallel. The scan process can span multiple threads that will work on the same table in parallel. The idea is to optimize the usage of available CPU cores. The resource manager can control the number of threads. The feature supplements parallel query.
In-Memory optimized arithmetic
There will be an In-memory optimized format for Oracle NUMBER type columns (don’t confuse NUMBER type with BINARY_FLOAT and BINARY_DOUBLE types). SIMD vector processing is a main feature of IMDB in order to perform one operation on multiple data within one CPU cycle. SIMD will also work on these numbers if a new parameter is configured (inmemory_optimized_arithmetic).
NVRAM support
NVRAM (non-volatile RAM) is slower but denser compared to DRAM. NVRAM retains data if power is turned off. DBIM will be able to use NVRAM. Smaller, hotter tables can be placed into DRAM while larger tables can be placed into NVRAM. An additional parameter (inmemory_xmem_size) will control the configuration of the extended memory capacity (XMEM).
Memory optimized access for Key-Value workloads
There will be a faster key-based lookup mechanism. Tables must be declared as MEMOPTIMIZE FOR READ and a parameter memoptimize_pool_size must be set. A lock-free In-Memory hash index structure will be created that allows a fast access for primary key based lookups to table data stored in row format.
Oracle In-Memory 18c preview by @dbinmemory #DOAG2017 pic.twitter.com/rvLYJPEfnC— Andreas Buckenhofer (@ABuckenhofer) 21. November 2017
Some more impressions: