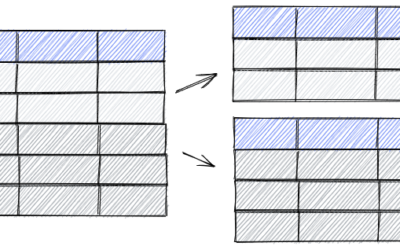
PostgreSQL partitioning guide
PostgreSQL partitioning is a powerful feature when dealing with huge tables. Partitioning allows breaking a table into smaller chunks, aka partitions. Logically, there seems to be one table only if accessing the data, but physically there are several partitions....

Anonymization techniques and data privacy
Anonymization techniques are essential for data analytics or in test/dev databases. Anonymization and pseudonymization are very different but often confused. GDPR does not apply to anonymized data anymore. GDPR is still applicable for pseudonymized data that can be...
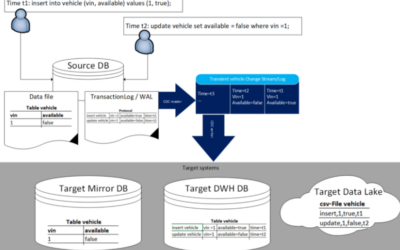
Log-based Change Data Capture - lessons learnt
My article on medium summarizes experiences from various projects with log-based change data capture (CDC). There are many use cases for which CDC is beneficial. Some DBs even have CDC functionality integrated without requiring a separate tool. The article first...
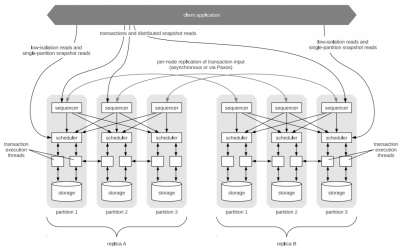
Calvin: distributed ACID transactions
Most distributed databases do not offer ACID transactions. The support of linear scalability is the main reason that distributed NoSQL databases like MongoDB, Cassandra, AWS DynamoDB and many others have reduced transactional support. Abadi et al. propose in a paper...

Study on Knowledge Sharing – Spotify Guilds / CoPs
Communications of the ACM published a study on Spotify Guilds / CoPs (Communities of Practice). A CoP is a group of people with similar interests who share their knowledge, solve problems or establish standards. The study examines the challenge of knowledge sharing...

The Zettabyte challenge
IDC published a White Paper about the challenge of Big Data Volume in a data-driven world. IDC expects that the data volume will grow from 45 Zettabyte (ZB) in 2020 to 175 ZB in 2025. The data will be produced in various forms like transactional data, text, voices,...

Columnar analytical databases for DWH and Data Analytics
The German magazine BI Spektrum published my article on analytical databases for DWH and Data analytics. The article discusses the characteristics of columnar databases and some analytical database categories. This blog contains a very brief summary....

Q&A on Data Integration and Big Data
Roberto Zicari did a Q&A with me about Data Integration and Big Data. Covered topics are Data integration, Big Data architecture, ETL, SQL, Hadoop, Data Lake, Data Catalog, Data Quality, education. The interview is available on odbms.org with the following...
NoSQL, NewSQL, cloud-native databases
The first NoSQL databases were created in the 2000s. Companies like Google, Amazon, Twitter & Co have developed their own databases for their specific needs. Over time, many of these databases were made available as open source. This blog post gives an overview of...
JSON and ISO SQL Standard
JSON was initially developed to exchange data via RESTful APIs (Representative State Transfer Application Programming Interface). The encoding is always Unicode, mostly UTF8. Programmable Web contains a variety of links to APIs like Twitter, LinkedIn, Strava, GitHub....
DOAG 2018
The annual DOAG 2018 conference took place from 20-NOV-2018 to 23-NOV 2018 in Nuremberg. As usual, the conference was excellent with a comprehensive community schedule. Core database topics are still covered by the majority of sessions but also with a focus on trends...
DOAG Big Data Days 2018
DOAG Big Data Days 2018 took place in Dresden from 20-Sep-2018 to 21-JUN-2018 with talks around Data capital, Data catalog, Streaming, Kafka, Data Lake, visualization, and geodata. There was also a hands-on workshop about Big Data SQL and connectors. This blog post...