The German magazine BI Spektrum published my article on analytical databases for DWH and Data analytics. The article discusses the characteristics of columnar databases and some analytical database categories. This blog contains a very brief summary.
BI-Spektrum 4/2019 enthält meinen Beitrag "Analytische Datenbanken im Umfeld von #DWH und #Analytics – ein Überblick" @tdwi_eu #columnar #inmemory #database pic.twitter.com/7tTnPZLtNV
— Andreas Buckenhofer (@ABuckenhofer) October 17, 2019
Characteristics of columnar analytical databases
Five essential characteristics of columnar analytical databases are:
- Columnar
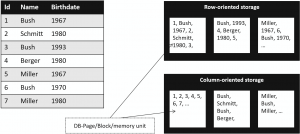
Organising data physically by storing columns in blocks (pages, in-memory units) instead of rows. The picture shows the classical row-oriented storage usually used in OLTP systems and columnar storage for analytical applications.
- In-Memory
Keeping data in memory. That’s nothing new: the combination with columnar data organisation and the following characteristics can lead to enormous performance boosts. - Compression
High compression due to having the same types of data in a block. - Zone maps (index skipping)
Using min-max values within blocks (or similar approaches) to skip reading blocks that are out of range. - SIMD (Vectorisation)
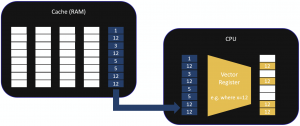
Processing multiple data during a single instruction, as shown in the image.
Categories
Categories of analytical databases are:
- Classical relational database management (RDBMS) with columnar In-Memory options
Classical databases have options to support OLTP and OLAP within the same system like Oracle IMDB, SQL Server columnstore index, SAP Hana, Db2 BLU, Db2 shadow tables, PostgreSQL CStore, MariaDB ColumnStore, etc. - Pure analytical databases
Databases using a shared-nothing architecture and organising their data columnar only like Exasol, Vertica, ClickHouse. - Cloud-only pure analytical databases
Cloud-only databases using a shared-nothing architecture with separation of storage and compute and organising their data columnar only like Snowflake, Amazon Redshift, Google BigQuery. - In-Memory OLAP (Cubes)
Highly specialised databases suited for Data Marts or planning like IBM Cognos TM1, Microsoft Analysis Services (MSAS), Palo. - Big Data OLAP
The columnar format within the Big Data ecosystem like Parquet, ORCfile, Kudu. - Graph databases
Graph stores organise data into edges and vertices for Recommender systems or Knowledge Graphs like Neo4j. These databases have no characteristics like columnar or SIMD, though.