Reference to blogs, tweets, discussions, etc that caught my attention during the last week.
Data Storage
“Introducing Espresso – LinkedIn’s hot new distributed document store” by Aditya Auradkar contains a detailled introduction (data model, architecture, key features, use cases, etc) into LinkedIn’s horizontally scalable, indexed, timeline-consistent, document-oriented, highly available NoSQL database Espresso. Espresso uses MySQL (InnoDB) for storage and secondary indexing including text search. The NoSQL DB became the primary source of truth for hundreds of terabytes. JSON is used to define database and table schemas while Avro is used to define document schemas and enabling schema evolution.
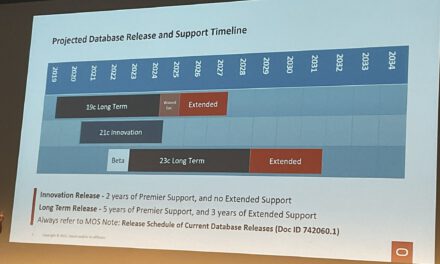
Oracle Non-CDBs are deprecated (but not [yet] desupported) with the beginning of release 12.1.0.2 as mentioned by Mike Dietrich on his blog “Non-CDB architecture of Oracle databases is DEPRECATED since Oracle Database 12.1.0.2“. Single-tenant architectures (a CDB with one PDB – no Multi-tenant license required) must be considered as replacement. Multi-tenant architectures will require an additional licence.
Data Flow
Kafka is well-suited for small messages. But what if messages are larger (than 10KB)? Gwen Shapira’s article “Handling large messages in Kafka” shows some possible confguration settings.
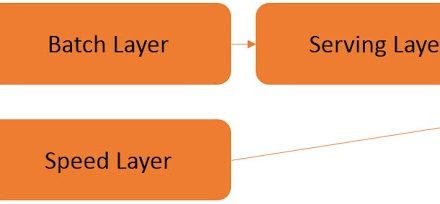
Martin Kleppmann’s slides are about “Making sense of stream processing“. Stream processing, event sourcing, complex event processing CEP are buzzwords that are often used for the same. The slides summarize some tools, reasons for streaming and architectures. The main part is about the difference of storing raw events (source of truth; immutable data: DB writes) and storing aggregated data (derived and denormalized; result data: DB reads).
Data Visualization
Animation of profit and revenue per second for 2013 for well-known companies by worldpayzinc.com: “See how quickly tech giants build wealth“.
Animation of monthly temperature measurements from over 135 years by Tom Randall and Blacki Migliozzi: “2014 Was the Hottest Year on Record“.
Data Divers
Big Data myths around data integration (still important), little data flaws (do still care about), etc are valuated in “Gartner Debunks Five of Biggest Data Myths” by storagenewsletter.com.
Overview and cheat sheet of RAID levels: “Which RAID level is right for me?” by adaptec.com.